Безспорно MS Excel е чудесна програма с милиони почитатели и потребители, с универсално приложение и независима по отношение на семантиката на данните и изчисленията, които се извършват.
Тази статия има за цел да:
- представи един малко по-различен подход при работа с големи масиви от данни
- позволи по-ефективно изпълнение на ежедневните задачи
- внесе динамика в процеса
- улесни тестването на варианти в нетривиални ситуации като работа с нови данни или изчисления различни от обичайните
Когато става дума за SQL заявки в съзнанието на повечето специалисти работещи с данни това се асоциира със сървър за бази данни, с често сложен процес на инсталация, настройки и др. недостъпни за потребители без права на администратори операции, но …
Съществува и алтернативно решение, което в комбинация с MS Excel е идеалният вариант:
- не е сървърна програма и работи локално на вашия компютър
- има минимални настройки (най-вече за удобство)
- освен че е безплатно, решението е ориентирано към задачи свързани с анализ гигабайти от данни.
Време е да се запознаете с DuckDB – специализирана, настолна (desktop) OLAP (Online Analytical Processing) база данни, с отворен код и разработена в Centrum Wiskunde & Informatica (CWI).
DuckDB е способна да извършва изключително бързи изчисления с огромни масиви от данни благодарение на колонната структура за съхранение на данните и векторизираните операции при изчисления.
Колонна структура на съхранение означава, че всяка колона от таблиците се съхранява като самостоятелен обект в базата данни, което позволява допълнителна компресия на данните, така че те да те минимално място, а това от своя страна позволява зареждането им директно в RAM паметта. От популярните продукти Power BI и повечето съвременни сървъри за аналитики (напр. ClickHouse) съхраняват данните в този вид.
Векторизирани операции означава, че изчисленията се извършват не стойност по стойност както е при традиционните итерактивни алгоритми, а паралелно с целите масиви от данни.
За да добиете по-добра представа за предимствата на DuckDB като помощен инструмент при работа с таблици на MS Excel ще решим две задачи, които често се срещат в практиката.
Задача 1
Разполагаме с данните за продажбите на продукти за 4 години (2014 – 2017) записани в самостоятелни файлове. Необходимо да изчислим по година и сегмент на клиента (Consumer, Corporate, Home Office):
- стойност на покупките
- общо количество продадени единици
- брой поръчки
- междинни суми по година, сегмент
За да изпълните заявките на вашия компютър е необходимо да заредите разширението
spatial, с помощта на което става четенето на MS Excel файлове. Подробности можете да намерите в Excel Import и Excel Export
Стъпка 1: обединяваме 4-те файла и ги превръщаме в източник на данни за следващите действия
WITH
sales
AS (
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2014.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2015.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2016.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2017.xlsx')
)
SELECT
*
FROM
sales
LIMIT 10;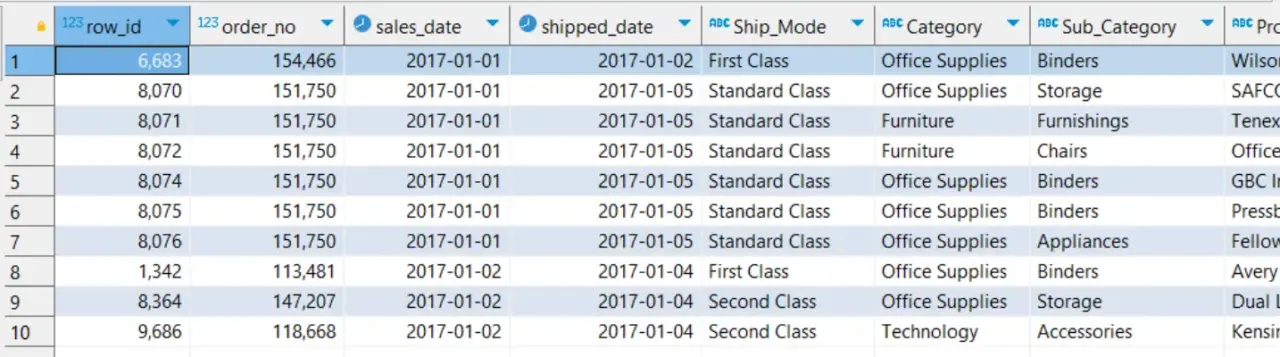
Данните от 4-те файла могат за удобство да се запишат и в таблица от базата данни.
CREATE OR REPLACE TABLE store_sales
AS
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2014.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2015.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2016.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2017.xlsx')Стъпка 2: SQL заявка с необходимите изчисления
WITH
sales
AS (
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2014.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2015.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2016.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2017.xlsx')
)
SELECT
YEAR(s.sales_date) sales_year
, s.segment
, ROUND(SUM(s.sales_amount),2) sales_sum
, ROUND(SUM(s.quantity)) sales_qnt
FROM
sales s
GROUP BY GROUPING SETS(
(sales_year, s.segment),
(sales_year),
(s.segment),
()
)
ORDER BY
sales_year
, s.segment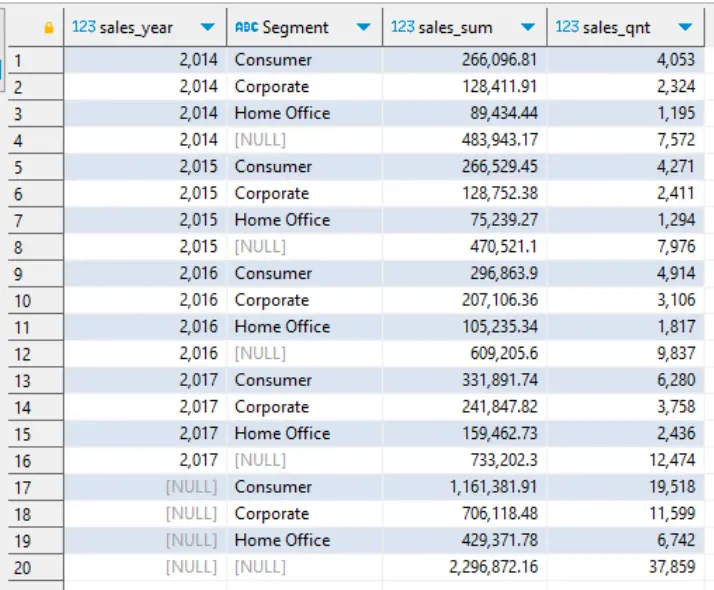
Стъпка 3: Експортираме данните обратно в MS Excel формат
COPY(
WITH
sales
AS (
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2014.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2015.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2016.xlsx')
UNION
SELECT * FROM st_read('Z:\data\xlsx\store-sales-2017.xlsx')
)
SELECT
YEAR(s.sales_date) sales_year
, s.segment
, ROUND(SUM(s.sales_amount),2) sales_sum
, ROUND(SUM(s.quantity)) sales_qnt
FROM
sales s
GROUP BY GROUPING SETS(
(sales_year, s.segment),
(sales_year),
(s.segment),
()
)
ORDER BY
sales_year
, s.segment
)
TO 'Z:\data\xlsx\store-sales-report.xlsx'
WITH ( FORMAT GDAL, DRIVER 'xlsx');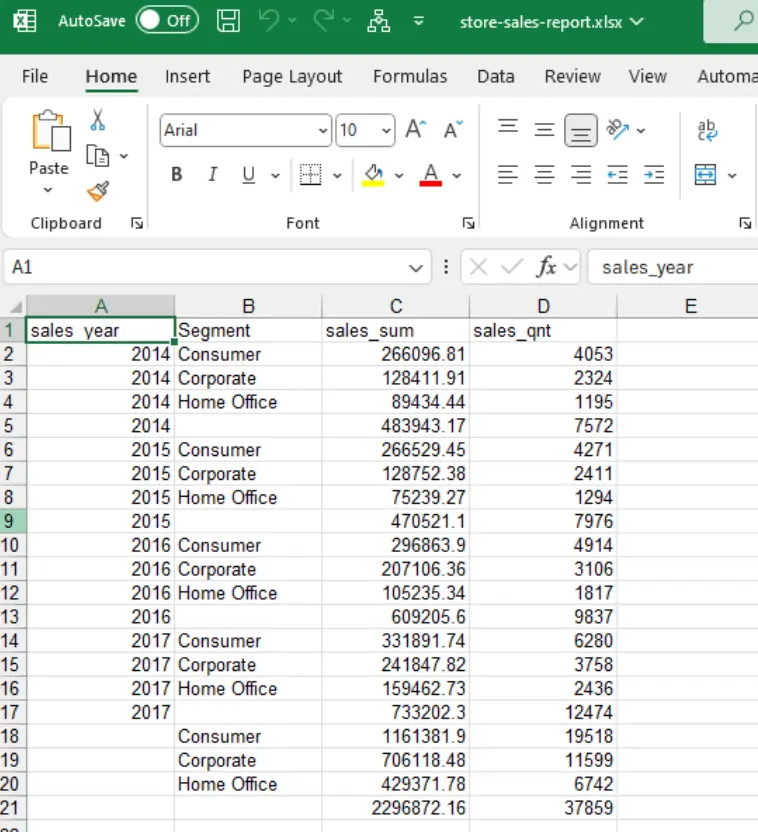
Задача 2
Разполагаме с продажбите през периода 2014-2017 година. Необходимо е за всяка година да се сравнят продажбите през текущ месец и същия месец миналата година като и да се изчисли изменението в парични единици и проценти.
Примерният резултат би изглеждал така:
| Year | Month | Sales | Sales LY | Diff | Diff % |
|---|---|---|---|---|---|
| 2014 | 1 | 500 | null | null | null |
| 2014 | 2 | 600 | null | null | null |
| … | … | … | … | … | … |
| 2015 | 1 | 700 | 500 | 200 | 40.00% |
| 2015 | 2 | 550 | 600 | -50 | 8.30% |
Стъпка 1: зареждане на данните и сумиране на продажбите по месеци за всяка година
SELECT
YEAR(order_date) sales_year
, MONTH(order_date) sales_month
, ROUND(SUM(sales)) sales_amt
FROM
st_read('Z:\data\xlsx\superstore-sales.xlsx')
GROUP BY ALL
ORDER BY
1
, 2
LIMIT 10;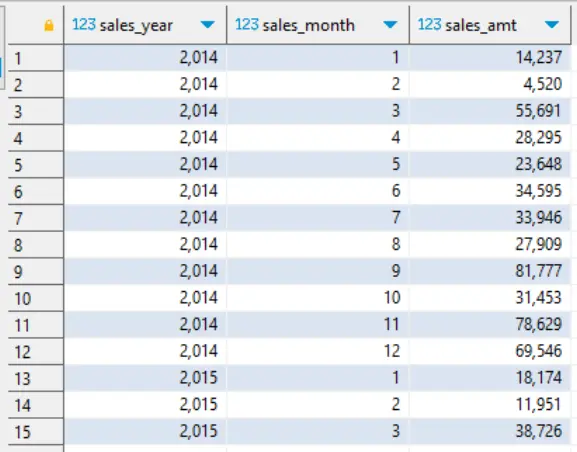
GROUP BY ALLе едно много удобно допълнение към стандартнатаGROUP BYклауза в DuckDB, позволяваща групирането да се извърши без изброяване на всички колони вSELECTчастта на заявката.
Стъпка 2: сравнение между текущ и същият месец миналата година
WITH
sales
AS (
SELECT
YEAR(order_date) sales_year
, MONTH(order_date) sales_month
, ROUND(SUM(sales)) sales_amt
FROM
st_read('Z:\data\xlsx\superstore-sales.xlsx')
GROUP BY ALL
ORDER BY
1
, 2
)
SELECT
s.sales_year
, s.sales_month
, s.sales_amt
, LAG(s.sales_amt, 12)
OVER( ORDER BY s.sales_year, s.sales_month ) sales_ly
, s.sales_amt - sales_ly diff
, ROUND(diff / sales_ly * 100,2) diff_perc
FROM
sales s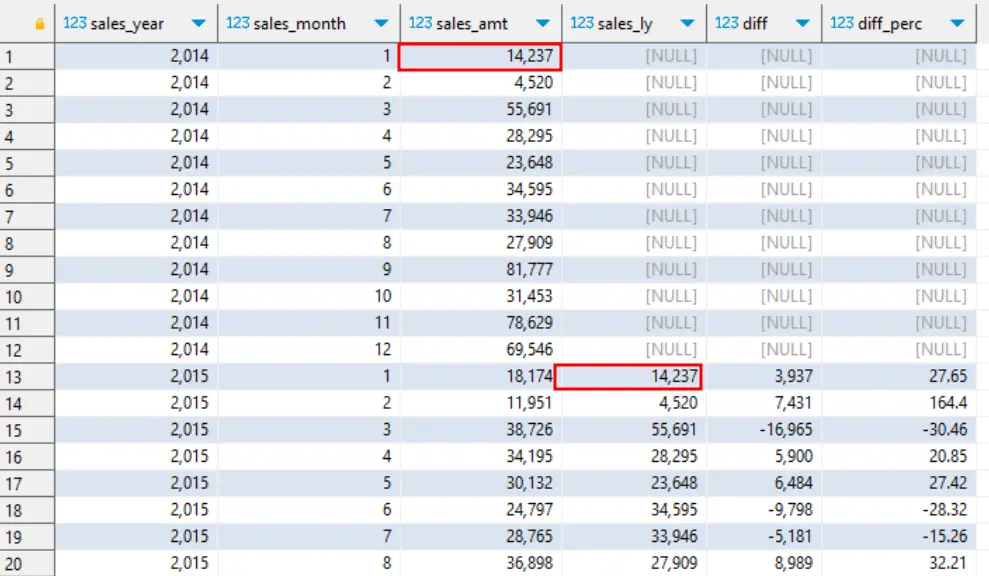
В стандартния SQL псевдонимите на колоните от
SELECTдиректно не могат да участват в изрази като използваните в заявката от примера (двата реда надFROM) и това е още едно удобно допълнение към езика SQL в DuckDB.
Стъпка 3: Експорт на резултатите в MS Excel
COPY (
WITH
sales
AS (
SELECT
YEAR(order_date) sales_year
, MONTH(order_date) sales_month
, ROUND(SUM(sales)) sales_amt
FROM
st_read('Z:\data\xlsx\superstore-sales.xlsx')
GROUP BY ALL
ORDER BY
1
, 2
)
SELECT
s.sales_year
, s.sales_month
, s.sales_amt
, LAG(s.sales_amt, 12)
OVER( ORDER BY s.sales_year, s.sales_month ) sales_ly
, s.sales_amt - sales_ly diff
, ROUND(diff / sales_ly * 100,2) diff_perc
FROM
sales s
)
TO 'Z:\data\xlsx\report.xlsx'
WITH ( FORMAT gdal, DRIVER 'xlsx');
Какво е различното при използвания подход?
Гъвкавост, динамика на процеса, ефективност
Езикът SQL дължи популярността си на своята гъвкавост и лекота в използването и изучаването му. Например ако в първата задача трябва да добавим още няколко години (файла), то към заявката ще добавим съответния брой UNION клаузи последвани от SELECT заявки.
В изразите с изчисления лесно можем да правим промени като например да извадим ДДС от стойността, да конвертираме в друга валута или да разместим колоните, да сортираме или да филтрираме резултатите по различни критерии – всички промени можем да направим за секунди.
SQL заявките са много близки до естествения език. Да си представим ситуация, в която на наш колега трябва да възложим задача. Бихме му казали нещо от типа на „Избери … от таблиците … където …“ и т.н., което преведено на SQL ще изглежда SELECT ... FROM ... WHERE ....
Близостта на SQL до естествения език позволява да поддържаме висока динамика в процеса на решаване на задачи и съставянето на заявките да тече почти паралелно с мисълта и с минимум допълнителни действия.
Автор: Дикран Хачикян