Възможността да превръщаме сурови данни в информация с цел взимане на ефективни бизнес решения до голяма степен се дължи на добре направен проучвателен анализ на данните (EDA – Exploratory Data Analysis). Той ни позволява да изследваме подробно това, с което разполагаме, като проучването може да се направи в два аспекта. Единият е чисто технически (какви са типовете данни – числа, дати, номинални стойности и т.н.), а другият е смислов (какво стои зад тези стойности и какво ни показват те).
В тази статия ще ви запозная с това какво представлява проучвателният анализ на данни и кои са важните стъпки, през които трябва да преминем, за да бъде направен успешно.
Какво е EDA и защо го извършваме?
По време на EDA преминаваме през различни етапи на анализа на данните, като използваме подходящи инструменти, например езиците за програмиране Python и R. Те ни позволяват да вникнем в данните и да се запознаем подробно с тях.
Проучвателният анализ е важна стъпка, която ни дава възможност да добием добра представа за данните и в последствие да подобрим получените резултати от анализа. Можем да открием тенденции и различия в данните, както и да достигнем до конкретни изводи, приближаващи ни до отговора на въпросите, които ни интересуват.
Как да изследваме данните и на кои въпроси трябва да отговорим?
Когато започваме да анализираме данните, трябва да уточним стъпките, през които да преминем. Една от първите е преглед на данните в технически аспект. Необходимо е да намерим отговор на въпросите: колко са редовете и колоните, от какъв тип са данните, какво ни показват описателните статистики, какъв е процентът на липсващи стойности, има ли наличие на необичайно високи или ниски стойности и др.
EDA в технически аспект
Общият брой редове и колони ни дава възможност да разберем какъв е размерът на извадката. От там вече можем да преценим дали данните са достатъчни или е нужно да извлечем още. Възможно е и извадката да е твърде голяма и да решим, че толкова много данни не са необходими за целите на изследването
ни.
След като сме добили представа за размера на извадката, можем да преминем към преглед на типа на данните, с които разполагаме. Характеристиките са разделени в 2 категории – качествени и количествени, като първите приемат нечислови стойности (пол, произход, град и т.н.), а вторите са числа, които можем да определим като дискретни (стойности от изброимо множество) или непрекъснати (стойности от неизброимо множество).
Има различни методи за трансформация и изследване на данните (визуализация и подходящи модели), които зависят от това какъв е типът на данните в извадката (числа, дати, текст и т.н.). Например ако данните съдържат качествени характеристики, в следващите стъпки на анализа можем да прегледаме тяхното честотно разпределение с помощта на таблици или визуализации.
Визуалният анализ ни позволява по-лесно да изследваме данните, като можем да правим сравнения и да видим тяхната изменчивост. Има изключително голям брой визуализации, от които да изберем подходящите за проучването. При категорийните променливи
можем да използваме стълбовидни диаграми, за да сравним различните категории на базата на конкретна числова характеристика. Ако имаме извадка за продажби на имоти, можем да видим при кой тип имот са най-високи цените или ако имаме данни за клиенти, можем да ги съпоставим по размер на доходите им.
Пример:
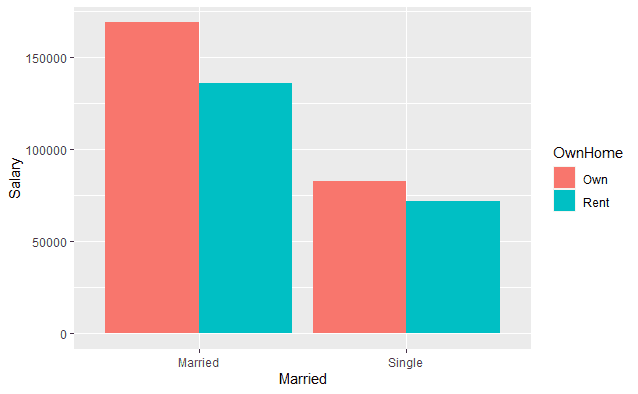
На визуалиацията е показана заплатата на клиенти в зависимост от тяхното семейно положение и това дали притежават собствено жилище или живеят под наем.
За числови данни освен класическите диаграми на разсейването и линейни диаграми, можем да използваме и графики на плътността на разпределението, хистограми, диаграми тип кутия, или да комбинираме графики и да видим разпределението на числовите променливи по 1 или повече категорийни.
Важно е да изследваме колко силна зависимост има между отделните характеристики и връзката им с целевата променлива. По този начин можем да достигнем до конкретни предположения за взаимното влияние на характеристиките . Връзката я изследваме първо между отделните характеристики и ако при някои има силна корелация, тогава се сблъскваме с проблем, наречен мултиколинарност. Той може да доведе до подвеждащи резултати от моделите за машинно обучение и в такива случаи е необходимо едната от характеристиките да се премахне. След това изследваме каква е връзката на числовите характеристики с целевата променлива. Това ни позволява да преценим кои от тях влияят най-много при определяне на стойностите ѝ.
Връзката между променливите можем да изследваме, като изчислим коефициент на корелация, използваме визуализации като диаграми на разсейването, корелационна матрица и др., или с помощта на различни статистически методи като ANOVA, Хи-квадрат, регресионен анализ и др. Точно кой ще използваме зависи от това какъв тип на данните се изисква от самия метод.
Пример:
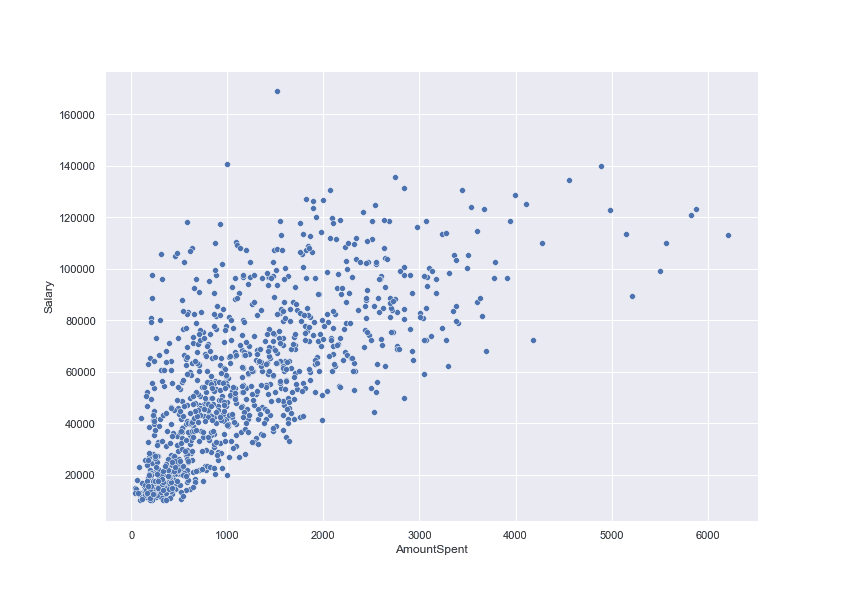
На визуализацията можете да видите диаграма на разсейването, показваща връзката между 2 характеристики – заплата на клиенти и стойност на покупките. На база на графиката можем да предположим, че най-вероятно, когато заплатата се увеличи, стойността на покупките също се увеличава.
Важно е да знаем с какви данни работим, за да можем да преценим какъв подход да предприемем по време на следващите стъпки на анализа.
Какво ни казват описателните статистики? е един много важен въпрос, който трябва да си зададем, когато анализираме данни. Тази стъпка е свързана с изчисляване на някои полезни мерки на разпределението на наблюденията, неговата форма и как са групирани стойностите.
Мерките на централна тенденция (мода, медиана и средна стойност) ни позволяват да видим кои са най-често срещаните стойности в данните. Средната стойност е добре познатото средно аритметично. Медианата е числото, което е в средата на подреден числов ред. Така 50% от данните са по-големи от медианата и 50% по-малки. Модата е най-често срещаната стойност, като не е задължително тя да е само една. Има разпределения и с повече от една мода.
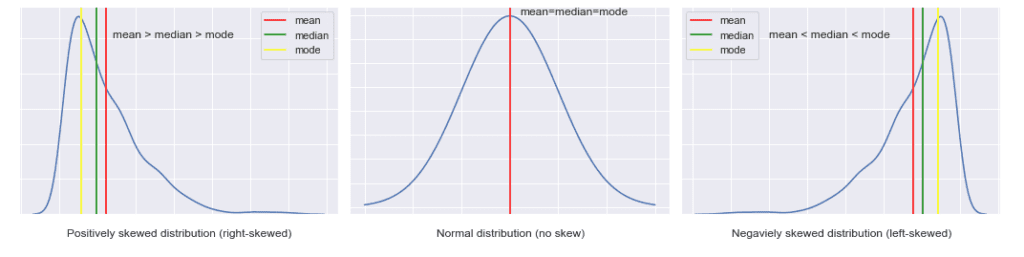
При нормалното разпределение мерките на централна тенденция съвпадат, а данните са симетрично разпределени около тях.
Други често използвани мерки са тези на разсейването. Те показват изменчивостта на данните. Такива например са размахът (разликата между най-високата и най-ниската стойност), стандартното отклонение и дисперсията, които ни дават възможност да добием представа колко далеч са наблюдаваните стойности от средната.
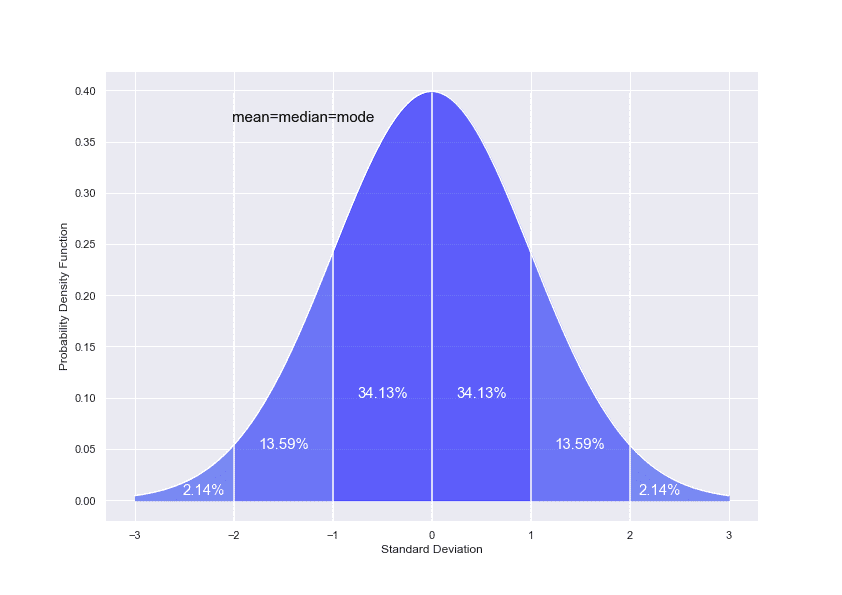
На визуализацията можете да видите графика на нормално разпределение, на която е показано какъв процент от данните се намират на определен брой стандартни отклонения от средната стойност.
Има ли липсващи стойности?
Един често срещан проблем, когато работим с данни, е наличието на липсващи стойности. Има много причини за появата им. Такива са например начина на събиране на данните или в резултат на грешки. Важно е да знаем причината за появата им, колко е процентът на липсващи стойности и да изберем по какъв начин да се справим с тях, тъй като те могат да доведат до получаване на грешни резултати.
За тяхната обработка можем да процедираме по 2 начина – премахване на редовете/колоните, в които липсват данни, или заместване с подходящи стойности. Трябва обаче внимателно да обмислим по какъв начин да се справим с тях, защото в противен случай можем да загубим важни за изследването данни или да изкривим резултатите. Ако изключим колона с липсващи стойности, може да се окаже, че сме премахнали такава, която е важна за изследването, а ако изтрием редове това намалява обема на извадката.
EDA в смислов аспект
Другата част от проучвателния анализ на данни, която протича паралелно с техническия, е свързана с това да разберем какъв смисъл стои зад данните. При нея трябва да използваме резултатите, получени по време на анализа в технически аспект, плюс знания от предметната област.
Необходимо е да познаваме сферата на дейност, с която са свързани данните и какви са текущите тенденции и предизвикателства в нея. Това ни позволява да преценим до колко добре са подбрани данните и дали още нещо ни е необходимо за изследването. Така можем да направим по-правилна преценка за това кои са важните характеристики в изследването.
Като притежаваме знания от предметната област можем да избегнем грешни изводи и да получим полезни резултати.
Каква е ползата от EDA?
Благодарение на проучвателния анализ можем да подобрим познанията си за данните, с които работим. Това помага много в следващите стъпки от процеса на изграждане на модел за машинно обучение. Дава ни представа кои характеристики да изберем, каква предварителна подготовка на данните е необходима, подобрява цялостната работа на модела и получаването на добър краен резултат.
Можете да получите повече информация за някои от въпросите, които разгледахме по-нагоре, в следните статии:
- Machine Learning: Как да обработим липсващи стойности при подготовката на данни за анализ?
- Machine Learning: Силата на визуализацията на данни. Коя графика какво ни показва?
- Machine Learning: Интерактивни визуализации с Python
Автор: Десислава Христова