При машинното обучение е много важен етапът на визуалния анализ, защото ни помага да добием представа за данните, като открием какви са зависимостите между отделните характеристики, какво е разпределението, дали има необичайно високи и ниски стойности и т.н. Визуализациите могат също да се прилагат и при представяне на крайните резултати от работата на моделите. С изготвянето на графики можем да разберем в коя посока на работа да се насочим и как по-добре да настроим избрания модел, така че да получим оптимални резултати.
В тази статия ще ви запозная с това защо е необходимо да изготвяме графики, когато се занимаваме с машинно обучение и коя е подходящата визуализация в зависимост това какво искаме да представим.
Избор на подходяща визуализация
Има различни типове графики, които се използват за представяне на данни, като всяка се прилага в определени случаи. За изготвяне на примерите, които ще видите по-надолу в статията, са използвани библиотеките Matplotlib и Seaborn на Python за визуализация на данни, както и 5 извадки:
- Iris – съдържа информация за видовете на цветето ирис и техните характеристики
- Tips – бакшиши, получени от клиенти в ресторант
- Bike buyers – данни за клиенти на магазин за велосипеди
- Bike sharing – данни за наемане на велосипед при различни метеорологични условия
- Telecom churn – клиенти на телекомуникационна фирма, които са се отказали или не от услугите ѝ
Хистограми и Графики на плътността на разпределението (density plot)
При машинното обучение в етапа на предварителен анализ често искаме да се запознаем с това какво е разпределението на данните, с които разполагаме. Това позволява да се определи дали дадени измервания се различават съществено от други или дали има натрупвания в краищата на разпределението. Подходящи визуализации за тази цел са хистограмата и графиката на плътността на разпределението.
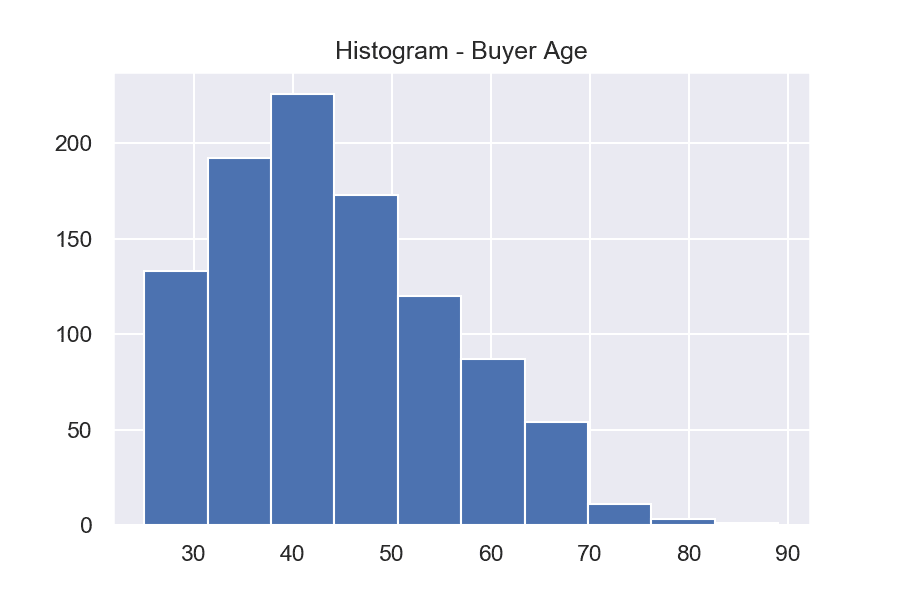
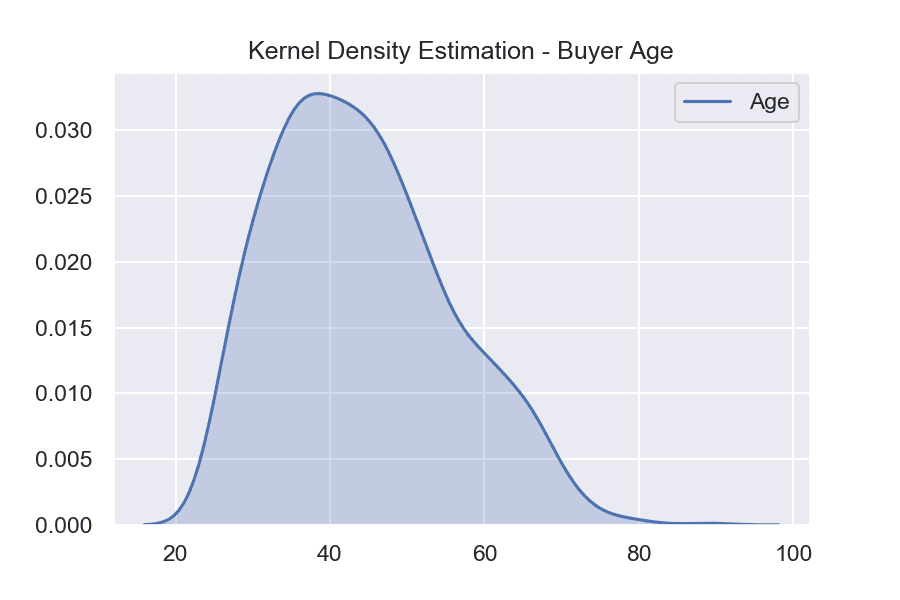
Извадка: Bike buyers
Визуализациите показват какво е разпределението на купувачи според тяхната възраст. При хистограмата данните се разпределят в няколко интервала, като броя на обектите във всеки от тях се изобразява с височината на колоните. Графиката на плътността на разпределението е изгладен вариант на хистограмата и позволява по-лесно да се определи каква е формата на разпределението, защото не зависи от броя колони. В нашия пример се вижда, че купувачите, които са най-често срещани, са на възраст около 40 години.
Комбинация от двете
Използването на хистограма и графика на плътността на разпределението едновременно е по-компактен начин да извлечем информация за това какво е разпределението на данните. Комбинацията може да се осъществи бързо и лесно благодарение на функциите distplot() и FacetGrid() на Seaborn.
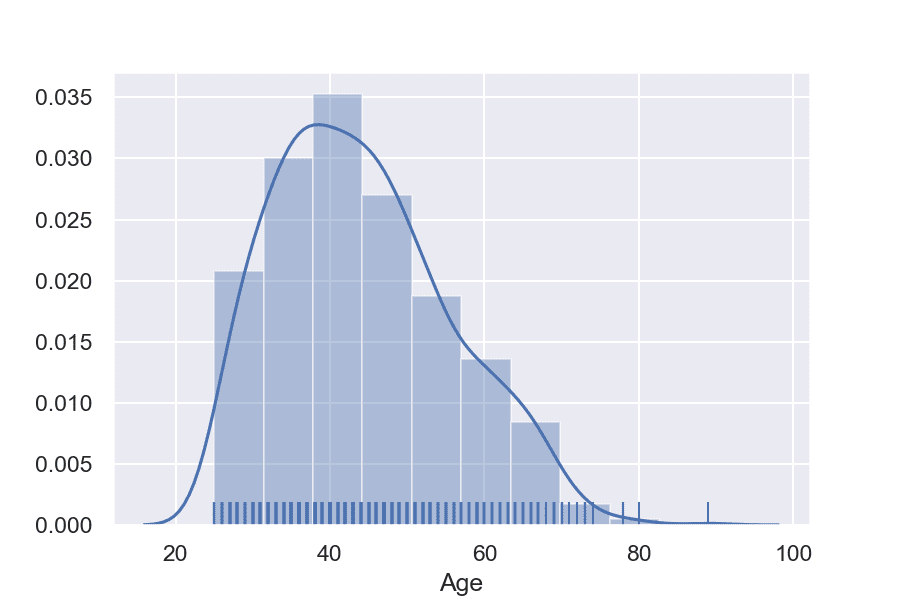
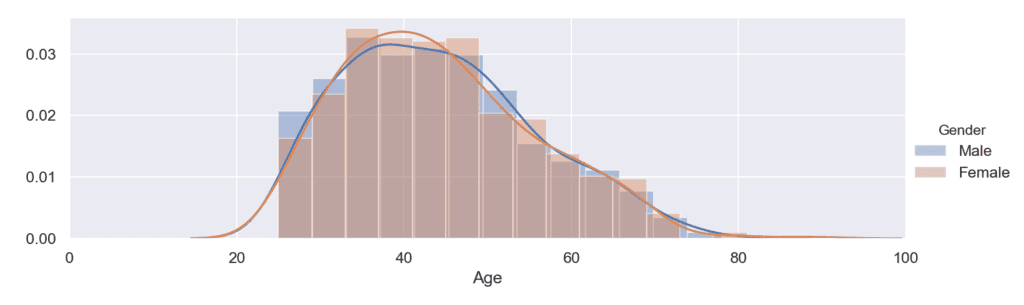
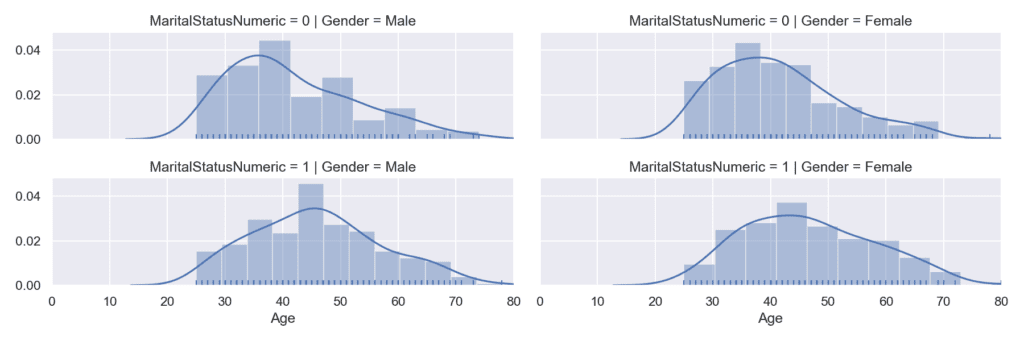
Извадка: Bike buyers
Отново на примерите можете да видите разпределението на купувачи според тяхната възраст, но в този случай са групирани по дихотомните променливи пол и семейно положение. Основното предимство тук е, че в 1 графика можем да видим разпределението на непрекъснати величини като възрастта, групирани само по 1 или по повече номинални характеристики.
Корелационни матрици
Корелационната матрица дава възможност да изобразим корелационните коефициенти при числови характеристики. Това е полезно, когато искаме да разберем между кои променливи има силна линейна зависимост.
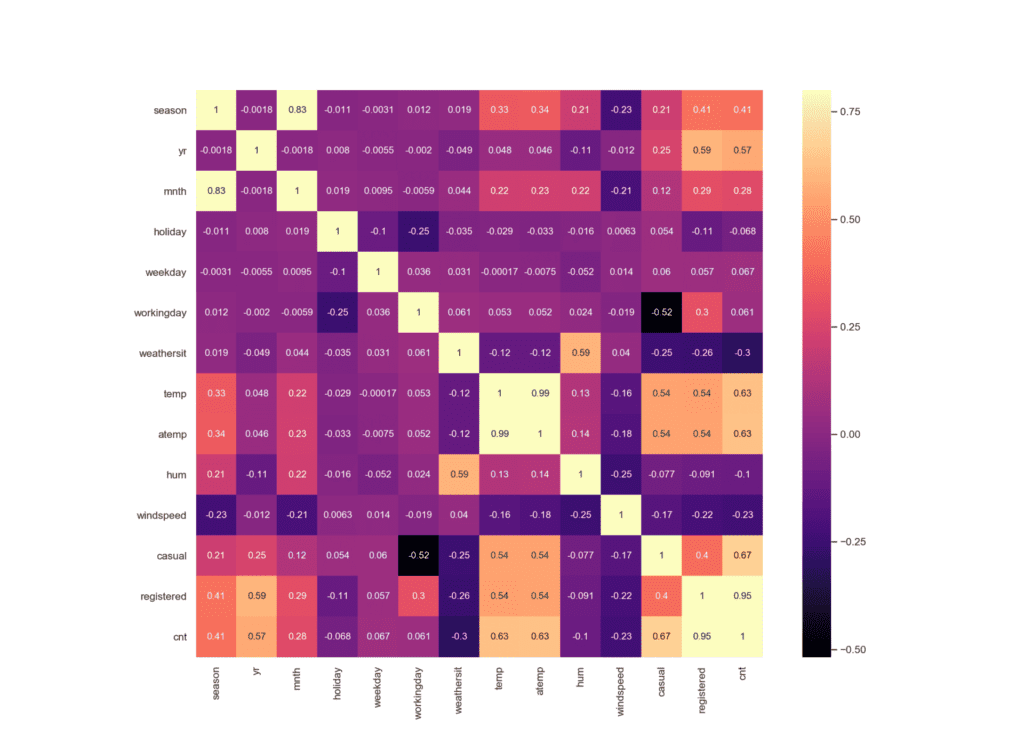
Извадка: Bike sharing
На визуализацията се вижда, че има силна положителна корелация между характеристиките температура (temp) и действителна температура (atemp) – 0.99, при броят регистрирани потребители (registered) и общият брой потребители (cnt) – 0.95, както и при месеците (mnt) и сезоните (season) – 0.83.
Диаграми на разсейване (scatter plot)
Диаграмите на разсейване могат да бъдат полезни, когато проверяваме каква е зависимостта между 2 различни величини. Чрез функцията scatter(), която предоставя Matplotlib, можем бързо и лесно да създадем стандартна диаграма на разсейването.
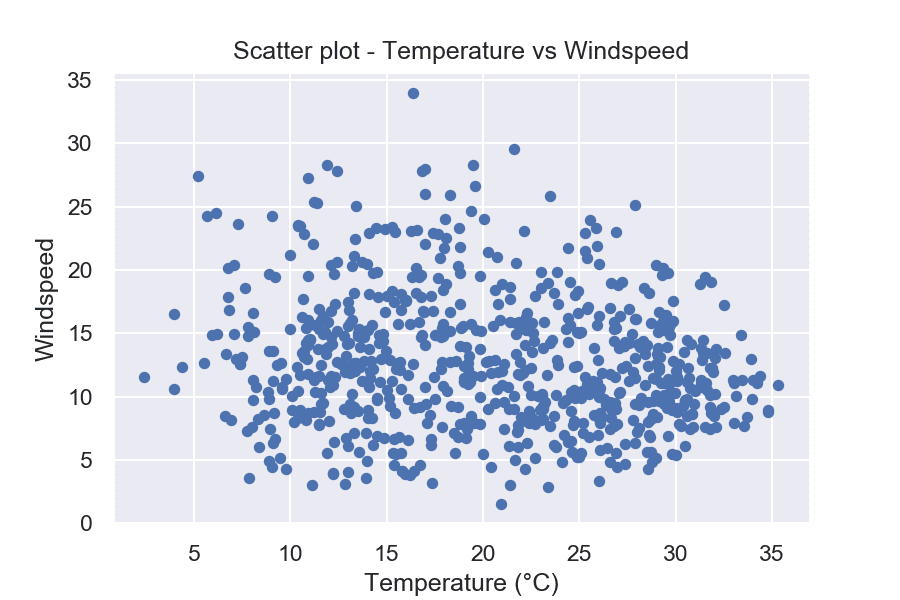
Извадка: Bike sharing
На този пример можете да видите зависимостта между температурата и скоростта на вятъра.
Може да се комбинира диаграмата на разсейването с хистограма по интересен начин чрез функцията jointplot() на библиотеката Seaborn. Това освен информация за връзката между двете променливи, ни дава и възможност да видим какво е разпределението на всяка от тях.
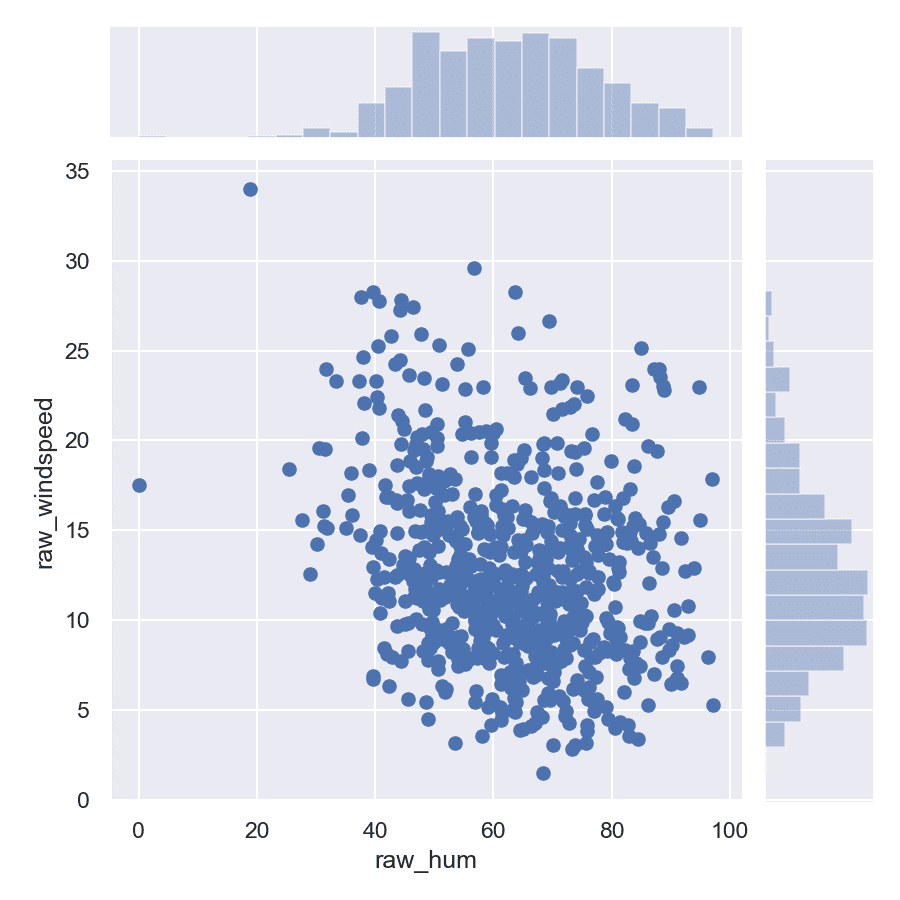
Извадка: Bike sharing
На графиката можете да видите връзката между скоростта на вятъра и влажността на въздуха, както и разпределението им.
Ако искаме да представим в обобщен вид зависимостта между всичките характеристики, това лесно може да стане чрез матрица, в която са изобразени множество диаграми на разсейването.
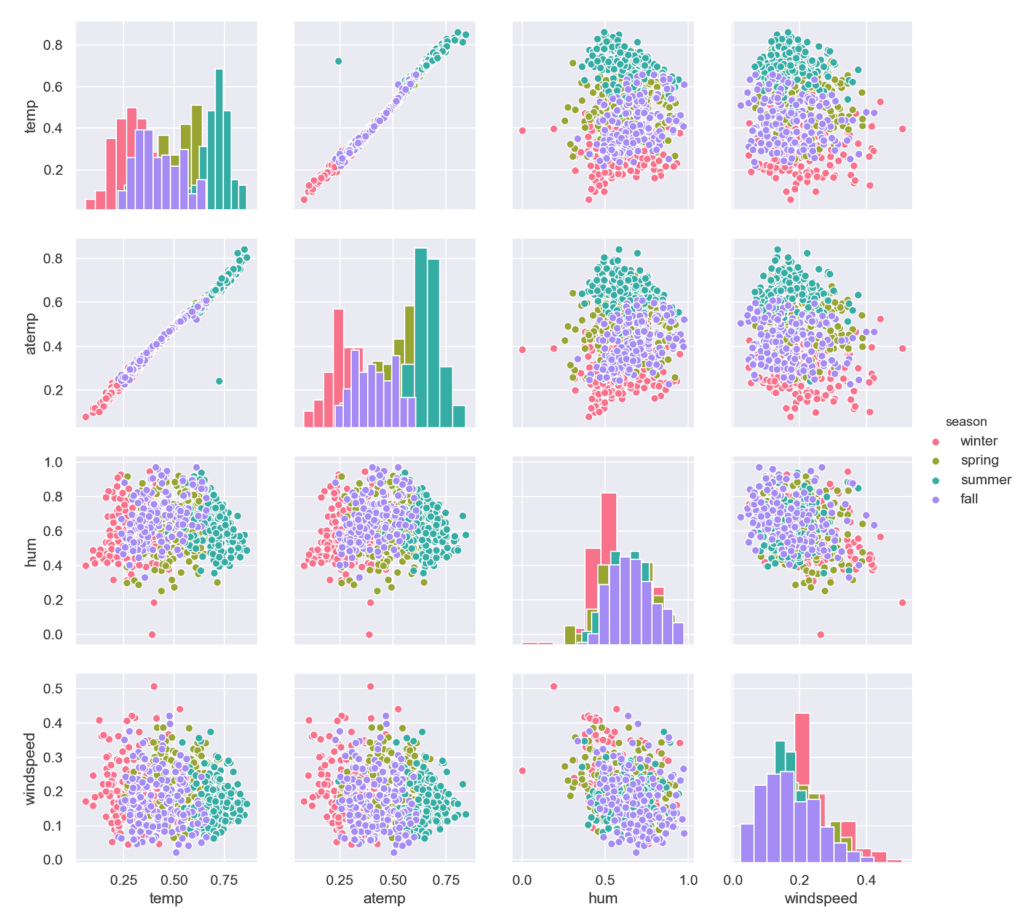
Извадка: Bike sharing
Използвана е функцията pairplot() на Seaborn, като по диагонала са изобразени хистограми. Ако искаме вместо това да представим графики на плътността на разпределението, може да стане, като се промени стойността на параметъра diag_kind на \’kde\’.
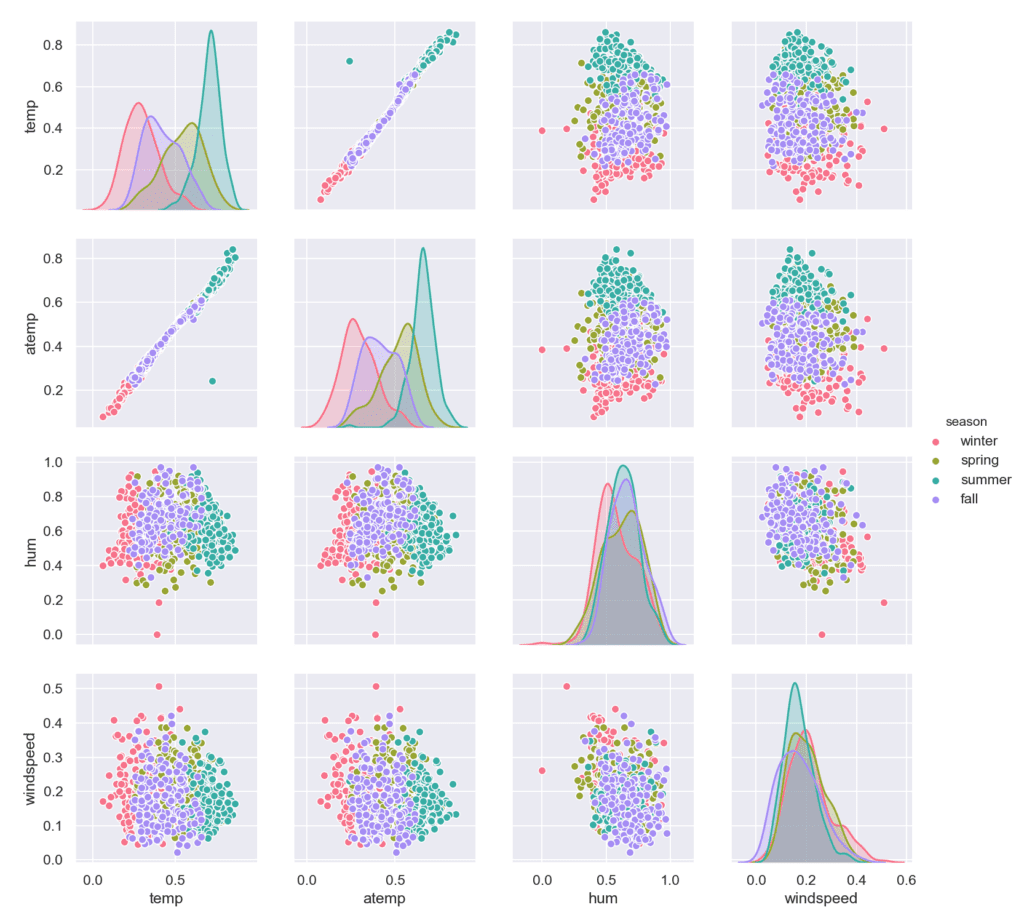
Извадка: Bike sharing
Примерите показват зависимостите между различни характеристики на времето (температура, действителна температура, влажност на въздуха и скорост на вятъра) през отделните сезони. Веднага прави впечатление, че има силна линейна зависимост между температурата (temp) и действителната температура (atemp).
Мехурчести диаграми (bubble chart)
Мехурчестите диаграми са подобни на диаграмите на разсейване. Разликата е в това, че включват 3 различни променливи вместо 2, като едната определя големината на точките.
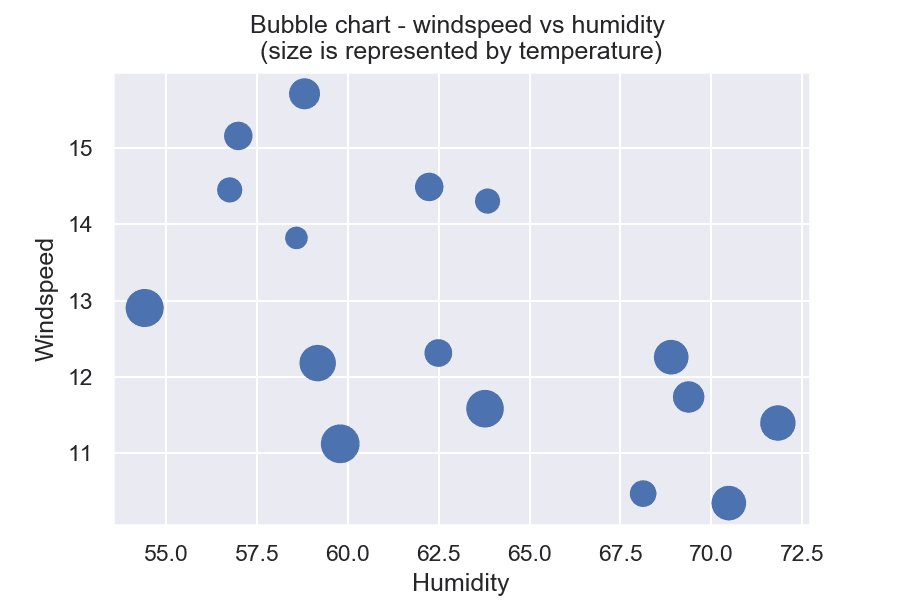
Извадка: Bike sharing
На примера можем да видим зависимостта между влажността на въздуха и скоростта на вятъра, като големината на мехурите се определя от стойността на температурата. Веднага се забелязва, че при по-ниска скорост на вятъра, температурата е по-висока.
Диаграми тип кутия (box plot)
Диаграмите тип кутия представят разпределението чрез описателни статистики на извадката и дават цялостна представа за данните. Те са много полезни при откриването на силно отличаващи се стойности (outliers).
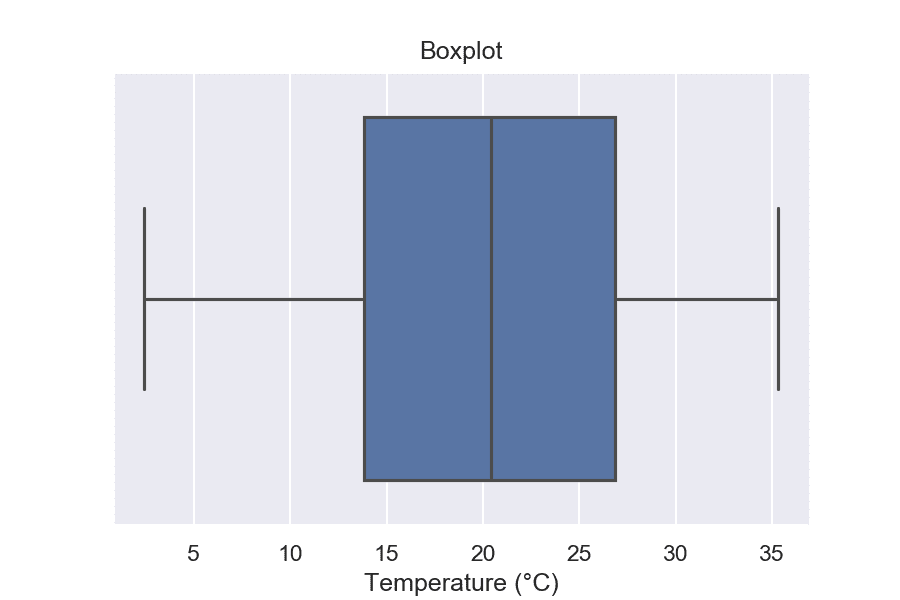
Извадка: Bike sharing
На тази визуализация ясно се вижда, че медианната температура е около 21 градуса и че 50% от данните лежат в диапазона между 14 и 27 градуса.
Quantile-Quantile (Q-Q) графики
Този тип графика ни позволява да разберем колко близко е разпределението на данните ни до нормалното чрез съпоставяне на квантили – от извадката и теоретични. Ако те са сходни, точките ще бъдат разположени близо или върху изчертаната права линия (y = x), която представлява теоретичните квантили. Може да се използва за определяне на необичайно високи или ниски стойности, но главно ни дава информаци за това на къде е изтеглена извадката.
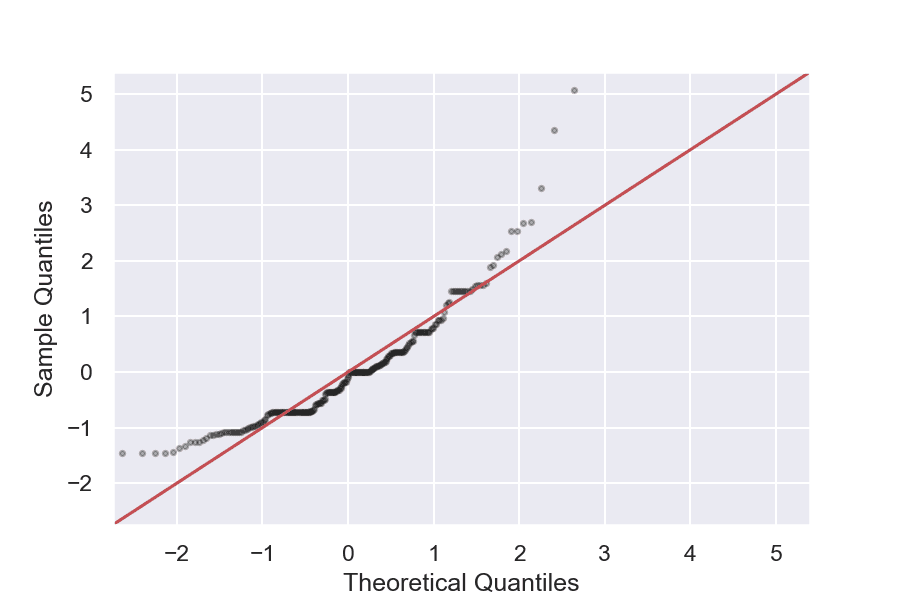
Извадка: Tips
Голяма част от точките на графиката не лежат на правата линия (y=x), което означава, че не се наблюдава нормално разпределение на данните за бакшиши. Можем също така да видим няколко отличаващи се стойности и че извадката е изтеглена вдясно.
Стълбовидни диаграми (bar chart)
Стълбовидните диаграми показват категории по едната ос и стойности по другата. Тя е лесна за разбиране и се използва, когато искаме да правим сравнения между отделните променливи – например ако искаме да видим честотата на категорийна характеристика.
Matplotlib и Seaborn предлагат голям набор от визуализации, които можем да използваме за тази цел, като за сравнение са доста подходящи стълбовидните диаграми.
- Хоризонтална стълбовидна диаграма
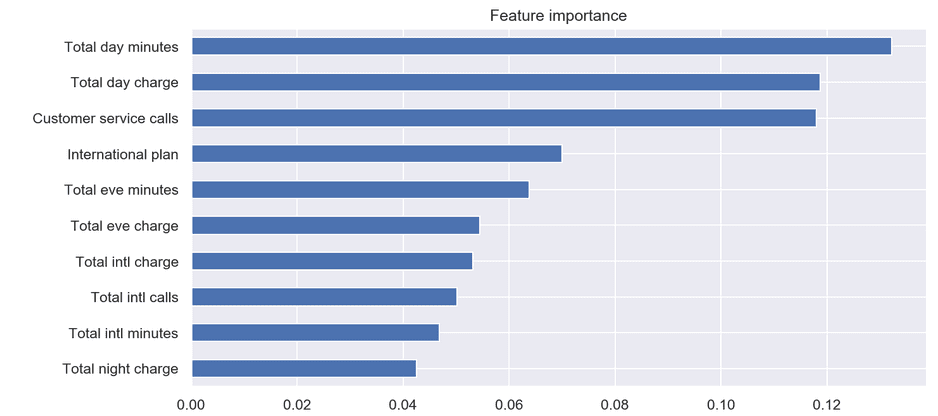
Извадка: Telecom-churn
- Вертикална стълбовидна диаграма
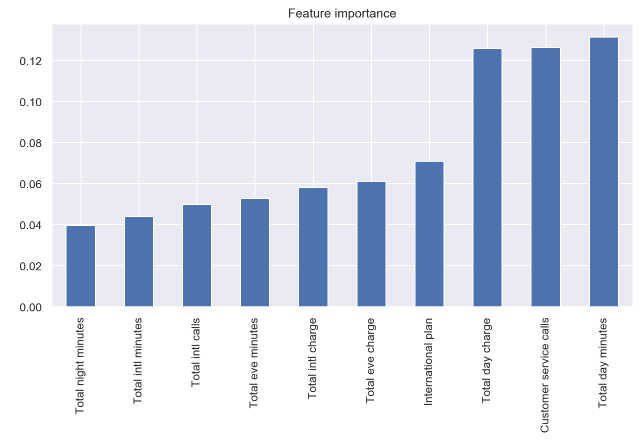
Извадка: Telecom-churn
В тези 2 примера много лесно можем да преценим разликите в значимостта на отделните характеристики чрез височината/ширината на стълбовете.
- Групирана стълбовидна диаграма
Този вид стълбовидна диаграма позволява да сравняваме данните на различни нива, като имаме 2 категорийни характеристики.
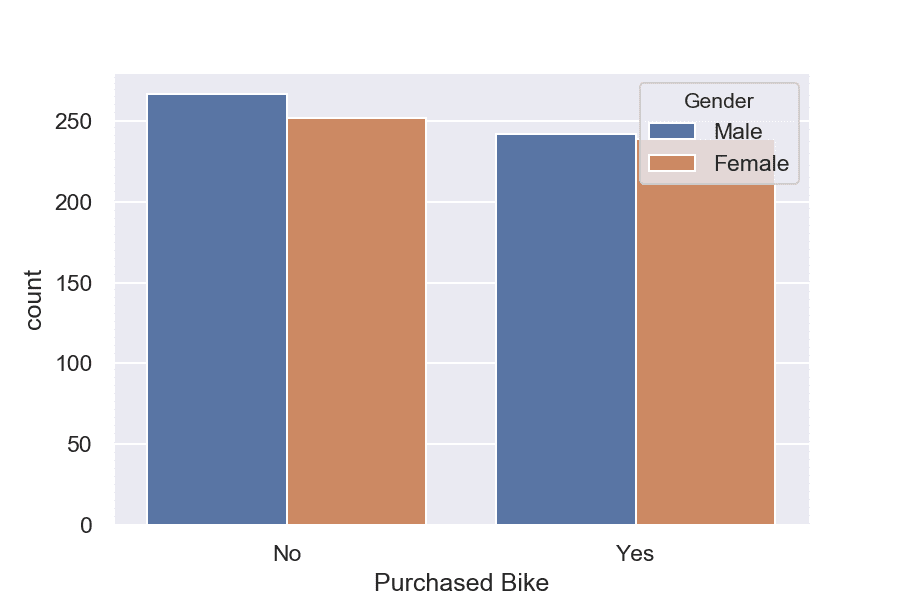
Извадка: Bike buyers
На графиката е изобразена групирана стълбовидна диаграма, която показва честотното разпределение на купувачи и некупувачи, разделени по променливата пол.
Линейни диаграми
Този тип диаграми са подходящи, когато искаме графично да представим числова характеристика с непрекъснати стойности. Могат да бъдат полезни както и за правене на сравнения чрез визуализиране на повече от една линия.
- ROC-крива и Кривата прецизност-пълнота (Precision-recall curve)
Receiver Operating Charactersitic (ROC) кривата и метриките прецизност и пълнота са начин, чрез който можем да оценим качеството на модел за класификация.
ROC кривата съпоставя TPR (True Positive Rate) и FPR (False Positive Rate), което дава информация за това до каква степен моделът правилно разпознава съответните класове.
Кривата прецизност-пълнота е начин да представим как се изменят стойностите на прецизността и пълнотата при различни прагове.
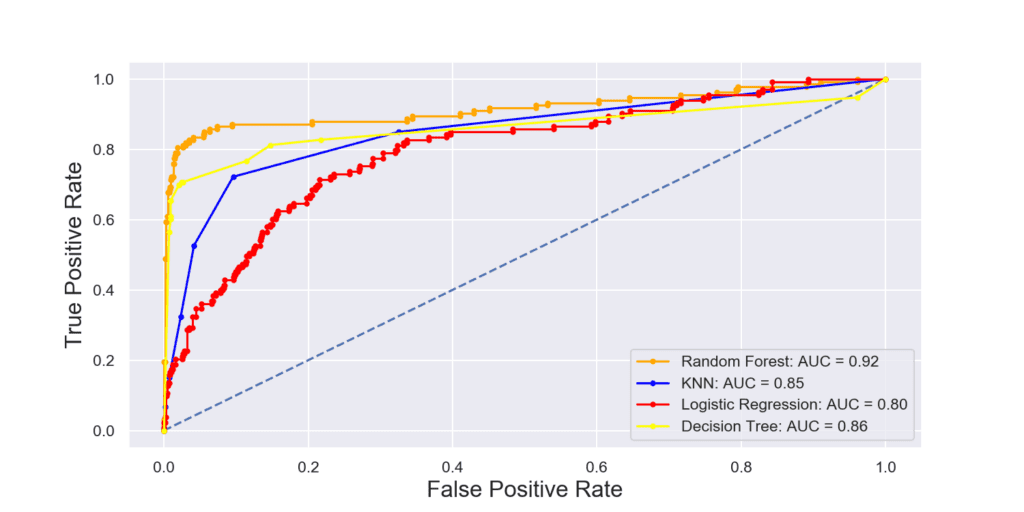
Извадка: Telecom churn
С този пример съпоставяме различни класификатори. Колкото по-близо до горния ляв ъгъл е ROC кривата, толкова по-високо е качеството на класификатора. При подходящо избрана комбинация от стойности на TPR и FPR, може да се определи оптималния праг (threshold) на класификация. На графиката можем да видим, че в нашия случай за предсказване на склонността клиент да се откаже от услугите на телекомуникационната фирма, моделът, използващ алгоритъм Random Forest, се справя най-добре.
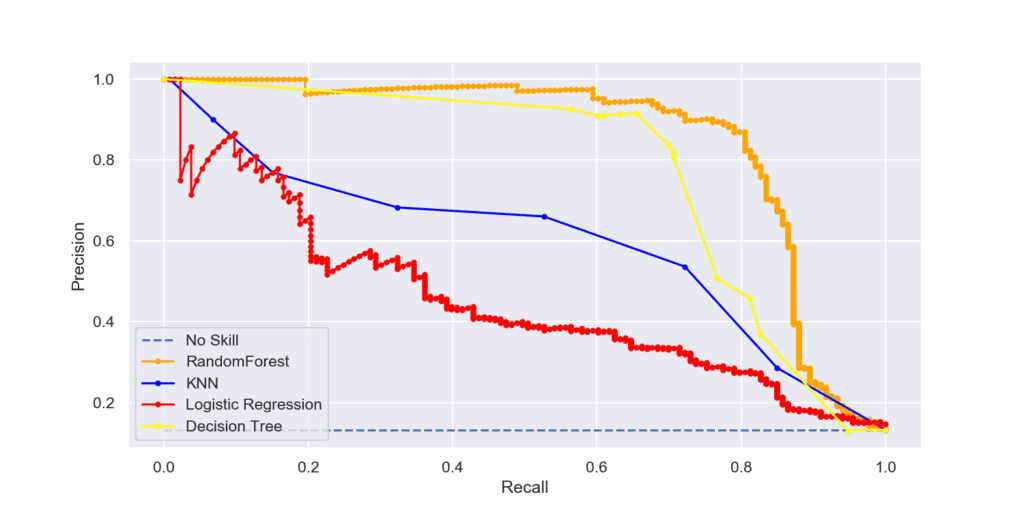
Извадка: Telecom churn
На кривата прецизност-пълнота, колкото по-близо е кривата до горния десен ъгъл, толкова по-качествен е класификаторът, защото и двете метрики са с високи стойности. В нашият случай отново Random Forest е с най-добри резултати.
- Learning curve
Чрез тази графика можем да направим сравнение на това колко добре се справя моделът върху обучаващото и тестовото множество при различен обем на извадката.
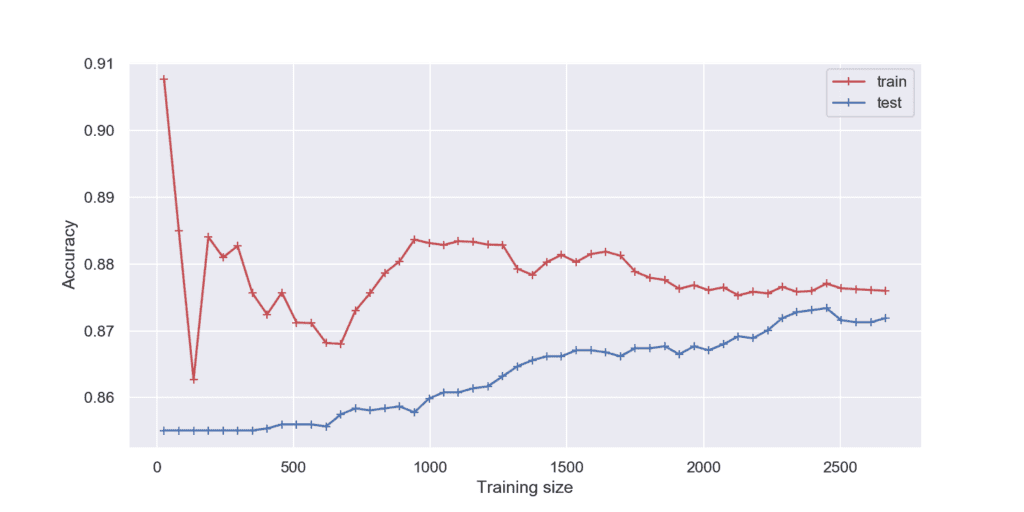
Извадка: Telecom churn
Когато визуализираме данните в линейна диаграма с 2 отделни криви, можем да оценим дали моделът работи добре с нови данни. С визуализацията става ясно, че колкото по-голям е обемът на извадката, толкова по-добри са резултатите.
- Паралелна диаграма (Parallel coordinates plot)
Паралелната диаграма изобразява линейно всеки един ред от данните за всяка колона и позволява лесно да видим разликите между стойностите за отделните характеристики. Тези диаграми са страхотни, когато искаме да сравним множество променливи и да видим какво е изменението им. Колкото по-прави са линиите, толкова по-силна е корелацията помежду им.
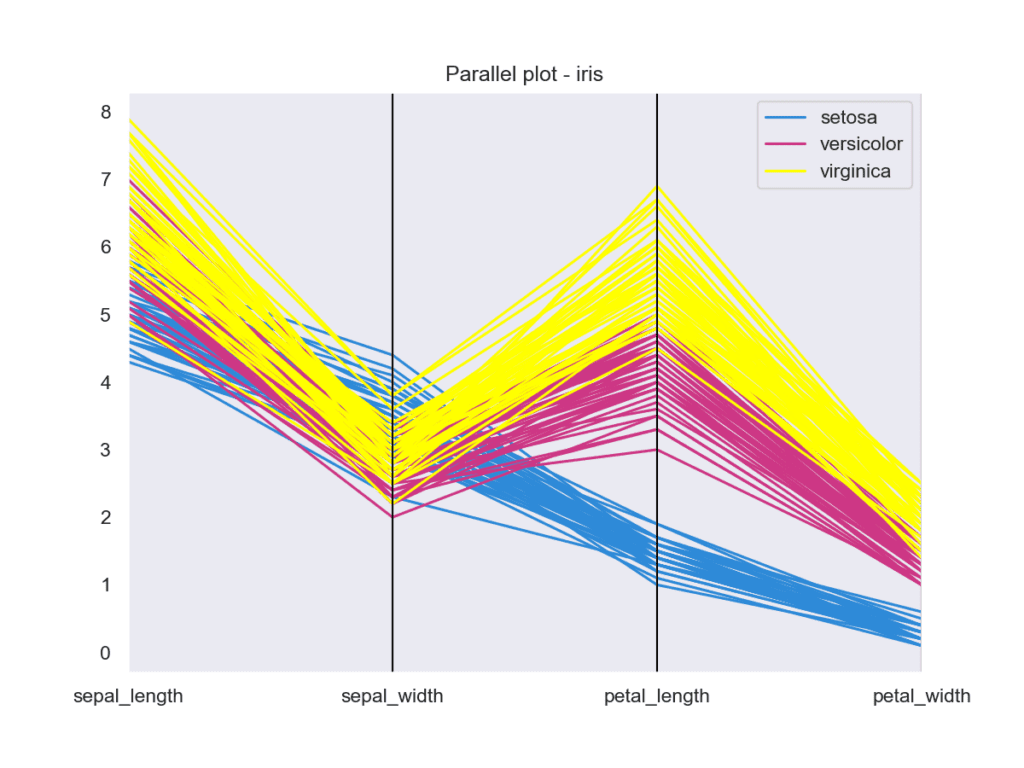
Извадка: Telecom churn
За този пример е използвана примерната база данни за цветето ирис. За всеки вид е изобразено изменението на стойностите на отделните характеристики. Става ясно веднага, че видът setosa е отделен от останалите.
Примерите с визуализациите можете да свалите от тук.
Можете да използвате Jupyter Notebook или друг подобен инструмент, за да ги изпълните.
Визуализациите на данните могат да бъдат и интерактивни. Вижте повече за библиотеките на Python за интерактивни визуализации тук.
Върху какво трябва да се фокусираме, когато изготвяме визуализации
При машинното обучение в етапа на визуален анализ на данните е нужно бързо и лесно да можем да достигнем до отговорите, които търсим. Визуализациите трябва да са изготвени така, че веднага да можем да извлечем нужната информация от тях. Добре е те да бъдат възможно най-опростени и компактни. В някои случаи е по-добре да гледаме и множество графики едновременно.
Каква е ползата от графичното представяне на данни?
Визуализацията на данни е изключително важна стъпка в машинното обучение. Без нея не можем да добием достатъчна представа за данните си и бихме изпуснали ценна информация, която би била необходима в следващите етапи от изграждане на модела.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с Python.
Автор: Десислава Христова