До скоро DAX Studio беше незаменим помощник в проучването на данни, разработването на метрики и тест за производителност на метриките. От края на 2023 година, с обновлението на Power BI, Microsoft включиха в новата версия инструмента DAX Query View, който има потенциала да измести DAX Studio.
До каква степен DAX Query View може да замести DAX Studio?
Да разгледаме какво ни дава всеки един от тези инструменти и да оценим може ли DAX Query View да замести DAX Studio пълноценно.
Специфични за DAX Query View възможности
- По-удобни клавишни комбинации
DAX Query View притежава удобни бързи клавиши за преместване и дублиране на редове и редица други, които внасят динамика и удобство при писане DAX заявки.
| Кл.комбинация | Действие |
|---|---|
| Alt + Up/Down | мести ред нагоре/надолу |
| Ctrl + D | маркира всички срещания на избран текст |
| Shift + Alt + Up/Down | копира ред нагоре/надолу |
| Ctrl + / | коментира/маха коментар от редовете |
| F5 | изпълнение на заявката |
- Доста добро дописване на променливи и метрики (Intellisense)
- Добавяне или промяна на метрики „с един клик“
При дефиниране на метрика, над нея се появява линк „Update model: Add new measure“, а при редактиране на съществуваща, линкът е „Update measure“ и метриката се добавя или обновява в посочената таблица.
За сравнение, при DAX Studio, метриките трябва да се пренасят една по една с копиране на изразите и прехвърлянето им в Power BI е тромава процедура.
Какво липсва в DAX Query View?
Най-големият недостатък на DAX Query View е липсата на каквито и да е било настройки, но не трябва да забравяме, че този инструмент все още не е част от стабилната версия на Power BI и е необходимо да се активира от Preview Features, за да се показва в интерфейса на програмата.
Специфични възможности на DAX Studio
- View Metrics
Това е доста полезна функция, която показва за всяка колона как е компресирана, колко място заема и др. и помага да открием резерви за оптимизация на модела на данните.
- Run Benchmark, Server Timings и Query Plan
Три много полезни инструмента, с които можем да сравняваме различни варианти на метрики и да изберем оптималния, да изследваме логическия и физическия план за изпълнение на заявките, да видим статистики за Storage Engine и Formula Engine на ядрото на Power BI.
- Резултати от заявка
В DAX Studio има възможност резултатите от заявка, освен да се видят на екрана, и да се експортират в различни формати: csv, MS Excel или директно копиране в Clipboard и след това да се пренесат в друга програма.
Практическа задача
Възможностите, предимствата и недостатъците на DAX Query View и DAX Studio могат най-добре да се видят с помощта на практическа задача.
Задача
Необходимо е да се разработи метрика, с която да се сравни средната стойност на поръчка по години (2014 – 2017), региони (West, East, Central, South) и сегмент на клиента (Consumer, Corporate, Home Office) и да се представят данните визуално.
Модел на данните
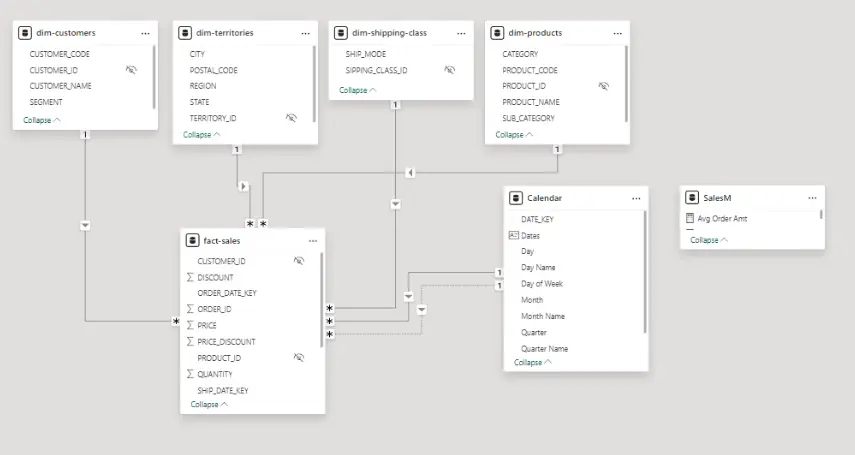
Кратко описание на таблиците от модела:
1) fact-sales Факт таблица с продажбите
2) dim-customers – данни за клиентите (тук се намира колоната със сегменти)
3) dim-territories – географски данни (тук се намира колоната с региони)
4) dim-shipping-class – данни за доставка
5) dim-products – данни за продуктите
6) Calendar – календарна таблица
7) Отделна таблица с метрики – SalesM
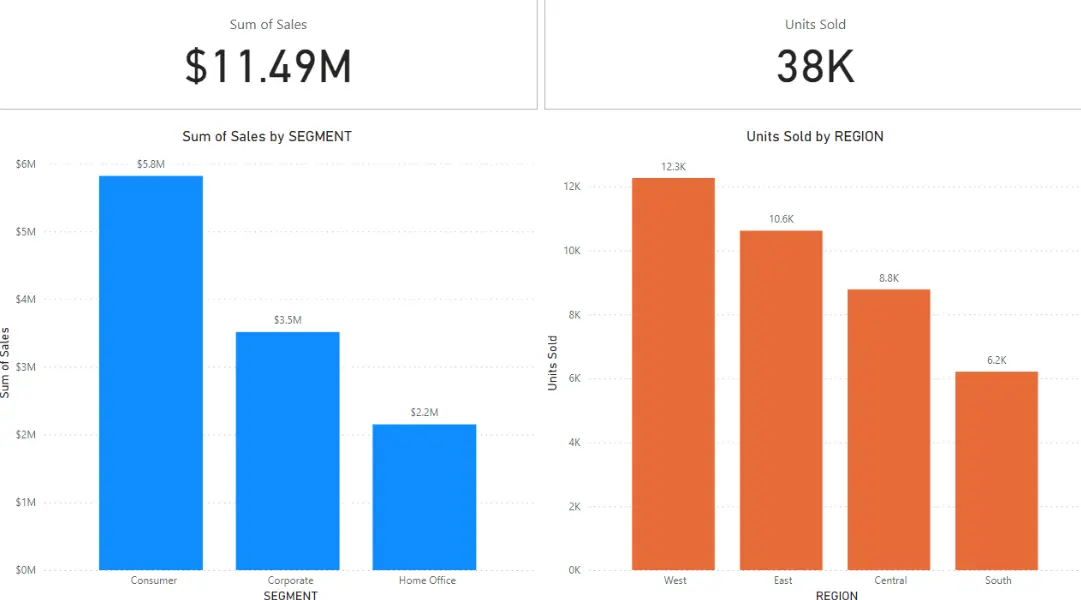
Общата стойност на продажбите е 11.49$ милиона, a общият брой продадени единици е 38 000.
Особеност на метриката, която трябва да се състави, е в това, че детайлността на факт таблицата е „продажба на продукт“, а ние трябва да получим резултат, отнасящ се до поръчките т.е. изчисленията трябва да са с данни с по-малка детайлност от тази в таблицата.
Това ясно се вижда от следващия фрагмент от факт таблицата. Например поръчка 100013 се среща 3 пъти, защото в нея има 3 продукта и когато изчисляваме средната стойност, трябва да използваме общата стойност на поръчката, а не на индивидуалните продажба.
| ORDER_ID | UNIT_PRICE | QUANTITY | DISCOUNT | SHIPPING_DAYS | PRICE | PRICE_DISCOUNT | CUSTOMER_ID | PRODUCT_ID | TERRITORY_ID | SIPPING_CLASS_ID | ORDER_DATE_KEY | SHIP_DATE_KEY |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100013 | 5.68 | 2 | 0 | 5 | 11.36 | 11.36 | 59 | 105 | 2 | 1 | 20171106 | 20171111 |
| 100013 | 8.73 | 1 | 0 | 5 | 8.73 | 8.73 | 59 | 104 | 2 | 1 | 20171106 | 20171111 |
| 100013 | 15.28 | 2 | 0 | 5 | 30.56 | 30.56 | 59 | 103 | 2 | 1 | 20171106 | 20171111 |
За по-лесно проследяване на действията и логиката, ще разделим решението на малки стъпки.
Стъпка 1: Основна заявка
Избираме два фактора – година и сегмент на клиента и изчисляваме общата стойност на продажбите.
EVALUATE
SUMMARIZECOLUMNS(
-- group by --
'Calendar'[Year],
'dim-customers'[SEGMENT],
-- expr --
"@Sales", [Sum of Sales]
)
ORDER BY
[Year]
, [@Sales] DESC
Резултат:
| Calendar[Year] | dim-customers[SEGMENT] | [@Sales] |
|---|---|---|
| 2014 | Consumer | 1358335.3534 |
| 2014 | Corporate | 647032.5567 |
| 2014 | Home Office | 462915.8246 |
| 2015 | Consumer | 1355935.9435 |
| 2015 | Corporate | 648794.7781 |
| 2015 | Home Office | 380170.658 |
| 2016 | Consumer | 1470278.3396 |
| 2016 | Corporate | 1054352.1396 |
| 2016 | Home Office | 525426.877 |
| 2017 | Consumer | 1634797.7643 |
| 2017 | Corporate | 1165928.1982 |
| 2017 | Home Office | 784093.6389 |
Стъпка 2: Израз, с който ще изчисляваме средната стойност
Изяснихме по-горе, че е необходима различна детайлност на данните т.е. резултатът трябва да е за поръчка, а не продаден продукт и като повечето неща в DAX, можем да избираме между няколко възможни решения.
Как да променим детайлността на данните без да създаваме допълнителни таблици в модела?
Вариант 1: с функцията SUMMARIZE() групираме по колона ORDER_ID.
VAR orders =
SUMMARIZE(
-- table --
'fact-sales',
-- group by --
'fact-sales'[ORDER_ID]
)Вариант 2: с функцията DISTINCT() извличаме неповтарящите се стойности в ORDER_ID.
VAR orders_ds =
DISTINCT('fact-sales'[ORDER_ID])Вторият вариант изглежда по-прост, но от това не следва автоматично, че е по-добър. По-късно ще изследваме разликите в производителността на двата варианта и ще определим оптималния.
Независимо от това кой от двата варианта ще използваме, средната стойност ще изчислим с функцията AVERAGEX().
Всички функции в DAX, които имат суфикс X се наричат функции итератори и те получават два параметъра: таблица и израз.
EVALUATE
SUMMARIZECOLUMNS(
-- group by --
'Calendar'[Year],
'dim-customers'[SEGMENT],
-- expr --
"@Sales", [Sum of Sales],
"@Avg Order Amt",
VAR orders =
SUMMARIZE(
-- table --
'fact-sales',
-- group by --
'fact-sales'[ORDER_ID]
)
VAR orders_ds =
DISTINCT('fact-sales'[ORDER_ID])
RETURN
AVERAGEX(orders, [Sum of Sales] )
)
ORDER BY
[Year]
, [@Sales] DESCРезултат:
| Calendar[Year] | dim-customers[SEGMENT] | [@Sales] | [@Avg Order Amt] |
|---|---|---|---|
| 2014 | Consumer | 1358335.3534 | 2592.243 |
| 2014 | Corporate | 647032.5567 | 2254.4688 |
| 2014 | Home Office | 462915.8246 | 2929.847 |
| 2015 | Consumer | 1355935.9435 | 2534.4597 |
| 2015 | Corporate | 648794.7781 | 2079.4704 |
| 2015 | Home Office | 380170.658 | 1990.4223 |
| 2016 | Consumer | 1470278.3396 | 2258.4921 |
| 2016 | Corporate | 1054352.1396 | 2498.4648 |
| 2016 | Home Office | 525426.877 | 2171.1854 |
| 2017 | Consumer | 1634797.7643 | 1866.2075 |
| 2017 | Corporate | 1165928.1982 | 2364.9659 |
| 2017 | Home Office | 784093.6389 | 2465.7033 |
В резултата получаваме стойността на поръчките за всеки сегмент по години и средната стойност на поръчка.
Стъпка 3: Дефиниране на метрики
Изразът за изчисляване на средната стойност можем да го дефинираме като метрика. В таблицата SalesM ще бъдат пренесени всички наши метрики с Add to model.
В процеса на решаване на задачата, се появява и още една идея за изчисляване на средната стойност:
VAR sales_amt = [Sum of Sales]
VAR n_orders = DISTINCTCOUNT( 'fact-sales'[ORDER_ID])
VAR result = DIVIDE( sales_amt, n_orders)
RETURN
resultВ този случай, просто разделяме стойността на поръчките на техния брой като допълнително можем променливата n_orders да дефинираме като метрика.
Така получаваме три варианта, от които трябва да изберем оптималния. Разликата между последния вариант и другите два е в това, че AVERAGEX() решението е по-универсално.
Например, ако се окаже, че за средна оценка е по-подходящо да изберем медианата, то можем да заменим
AVERAGEX()сMEDIANX(), но не можем да получим медианата, като разделим стойността на поръчките на техния брой.
DEFINE
MEASURE SalesM[Avg Order Amt A] =
VAR orders =
SUMMARIZE(
-- table --
'fact-sales',
-- group by --
'fact-sales'[ORDER_ID]
)
VAR orders_ds =
DISTINCT('fact-sales'[ORDER_ID])
RETURN
AVERAGEX(orders, [Sum of Sales])
// -- N Ordes --
MEASURE SalesM[N orders] =
DISTINCTCOUNT( 'fact-sales'[ORDER_ID])
// -- Avg Order Amt B --
MEASURE SalesM[Avg Order Amt B] =
VAR sales_amt = [Sum of Sales]
VAR n_orders = [N orders]
VAR result = DIVIDE( sales_amt, n_orders)
RETURN
result
EVALUATE
SUMMARIZECOLUMNS(
-- group by --
'Calendar'[Year],
'dim-customers'[SEGMENT],
-- expr --
"@Sales", [Sum of Sales],
"@Avg Order Amt A", [Avg Order Amt A],
"@Avg Order Amt B", [Avg Order Amt B]
)
ORDER BY
[Year]
, [@Sales] DESC
Резултат:
| Calendar[Year] | dim-customers[SEGMENT] | [@Sales] | [@Avg Order Amt A] | [@Avg Order Amt B] |
|---|---|---|---|---|
| 2014 | Consumer | 1358335.3534 | 2592.243 | 2592.243 |
| 2014 | Corporate | 647032.5567 | 2254.4688 | 2254.4688 |
| 2014 | Home Office | 462915.8246 | 2929.847 | 2929.847 |
| 2015 | Consumer | 1355935.9435 | 2534.4597 | 2534.4597 |
| 2015 | Corporate | 648794.7781 | 2079.4704 | 2079.4704 |
| 2015 | Home Office | 380170.658 | 1990.4223 | 1990.4223 |
| 2016 | Consumer | 1470278.3396 | 2258.4921 | 2258.4921 |
| 2016 | Corporate | 1054352.1396 | 2498.4648 | 2498.4648 |
| 2016 | Home Office | 525426.877 | 2171.1854 | 2171.1854 |
| 2017 | Consumer | 1634797.7643 | 1866.2075 | 1866.2075 |
| 2017 | Corporate | 1165928.1982 | 2364.9659 | 2364.9659 |
| 2017 | Home Office | 784093.6389 | 2465.7033 | 2465.7033 |
Стъпка 4: Кой вариант е по-добър?
За избора на оптимален вариант трябва да използваме DAX Studio, тъй като в DAX Query View няма подобна функционалност.
Първият инструмент, с който можем да тестваме заявката и метриките, е Server Timings, като при използването му не трябва да забравяме да включим бутона Clear on Run, за да се изчиства кеша на заявките преди всеки тест.
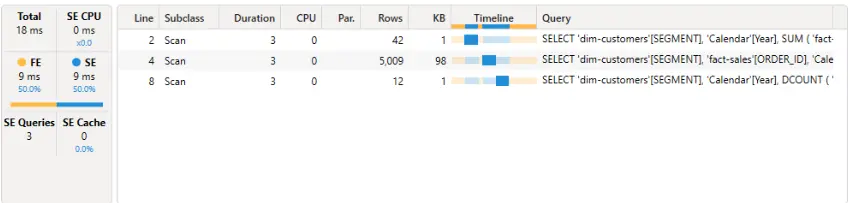
- Storage Engine (SE) – отговаря за достъпа до данните и част от изчисленията. Може да работи паралелно.
- Formula Engine (FE) – извършва онези изчисления, които не се поддържат от SE (например, ако с
ROUND()закръглим резултатите).
Получаваме за FE и за SE по 9 ms време за изпълнение на заявката като SE изпълнява паралелно три заявки.
При работа със Server Timings е добре да изпълним заявката няколко пъти, тъй като върху времето за изпълнение оказва влияние общото натоварване на системата и задачите, които изпълнява операционната система.
Удобен инструмент представлява и Run Benchmark, с който могат да се пуснат многократни тестове при „студен“ и „топъл“ кеш, както и обобщени и детайлни статистики за изпълнението на заявката.
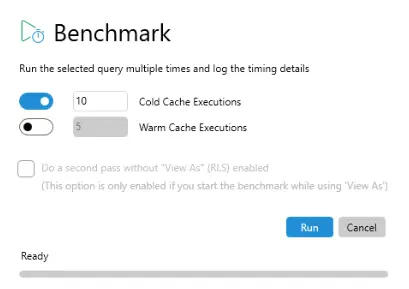
За нашия тест ще използваме по-тежкият режим – „студен“ кеш, и 10 изпълнения на заявката.
Вариант 1: SUMMARIZE()
| Cache | Statistic | TotalDuration | SE Duration |
|---|---|---|---|
| Cold | Average | 139.1 | 45.8 |
| Cold | StdDev | 73.8939931403238 | 41.8457484897411 |
| Cold | Min | 37 | 3 |
| Cold | Max | 224 | 136 |
Вариант 2: DISTINCT()
| Cache | Statistic | TotalDuration | SE Duration |
|---|---|---|---|
| Cold | Average | 115.8 | 43.2 |
| Cold | StdDev | 90.6492630355531 | 43.2352736650167 |
| Cold | Min | 33 | 4 |
| Cold | Max | 357 | 155 |
DISTINCT() дава малко по-добра производителност, като средните времена са с по-ниски стойности, минималните времена почти съвпадат, а максималните при SUMMARIZE() са по-ниски. но като окончателен вариант оставяме в метриката DISTINCT().
Ако решите да проведете тестовете самостоятелно, то може да получите по-различни стойности от дадените в таблицата.
Всички изводи по отношение на функциите
DISTINCT()иSUMMARIZE(), както и взетите решения, се отнасят за конкретния модел и данни т.е. не може да твърдим, чеDISTINCT()по принцип е по-бърза.
SUMMARIZE()e по-универсална функция отDISTINCT(). Например, ако трябва да групираме по няколко колони, няма да може да използвамеDISTINCT().
Вариант с DIVIDE()
| Cache | Statistic | TotalDuration | SE Duration |
|---|---|---|---|
| Cold | Average | 71.2 | 29.1 |
| Cold | StdDev | 47.3539861046565 | 32.2712462314881 |
| Cold | Min | 10 | 3 |
| Cold | Max | 172 | 101 |
Като резултат получаваме стойности, които са по-ниски от тези при DISTINCT() и окончателно се спираме на метриката за изчисляване на средната стойност:
DEFINE
MEASURE SalesM[Avg Order Amt B] =
VAR sales_amt = [Sum of Sales]
VAR n_orders = [N orders]
VAR result = DIVIDE( sales_amt, n_orders)
RETURN
resultВ Power BI има инструмент, наречен performance analyzer, но с него се изчислява производителността на визуален компонент и освен това, той не дава подробна статистика за изпълнението.
Визуално представяне на данните
За визуализация на данните избираме стълбова диаграма и добавяме необходимите колони и метрика.
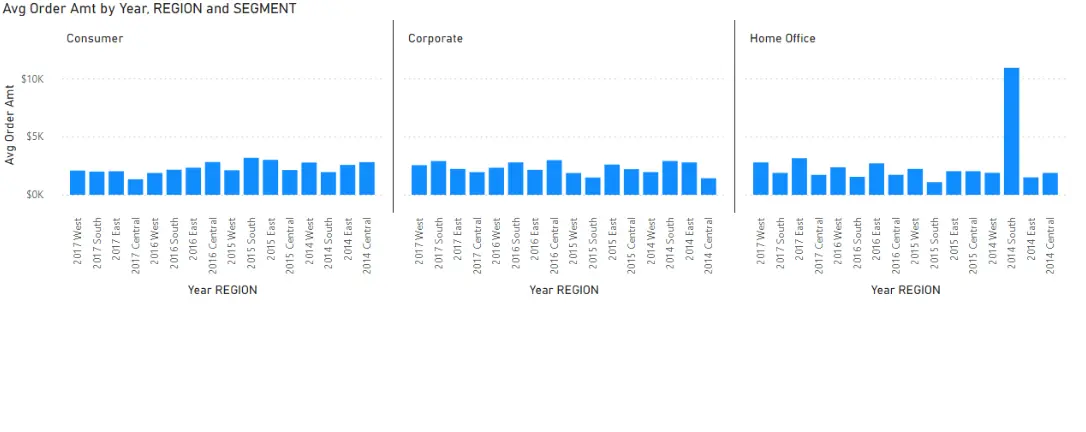
Заключение
Като заключение може да се каже, че DAX Query View като цяло е удобен инструмент за съставяне на DAX заявки и разработка на метрики. Разбира се има още какво да се подобрява в него, но с времето се надявам да става все по-добър.
DAX Studio за момента компенсира важна част от липсващата функционалност. В момента, в който тя се появи (ако се появи), DAX Studio може да служи като алтернативно средство за работа с DAX и не трябва да забравяме, че DAX Studio също не е спрял развитието си.
Използваните данни и решението на задачата можете да изтеглите от тук.
Искате да научите повече за Power BI?
Включете се в курса Power BI: Анализ на данни и изготвяне на отчети.
Автор: Devise Expert